Next: Parameters Up: TestInterp Previous: Running the Tests Contents
When is a Test Result ``Ok''?
All other things being equal, we can't expect any of our error normspart951 to be any smaller than a few times machine epsilonpart952 for the floating-point type in question. Moreover, if we're taking
![]() th derivatives in the interpolation, then since we're dividing by
th derivatives in the interpolation, then since we're dividing by
![]() in the computation, the error norms will typically
be a factor of
in the computation, the error norms will typically
be a factor of
![]() larger than they would be if no
derivatives were being taken.
larger than they would be if no
derivatives were being taken.
To aid in judging the test results, we thus also print a set of
``scaled error norms'', where each ``raw'' error norm is divided by
its ``minimum plausible'' value
![]() .
.
We specify a set of 4 scaled error norm thresholds as
parameters to the test driver, a ``low'' and a ``high'' threshold
for each of the RMS-norm and ![]() -norm scaled error norms.
Finally, we classify the outcome of each test as follows:
-norm scaled error norms.
Finally, we classify the outcome of each test as follows:
- ok
- if both the RMS-norm and the
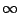 -norm scaled errors
are
-norm scaled errors
are 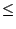 their ``low'' thresholds.
their ``low'' thresholds.
- marginal
- if at least one of the RMS-norm and the -norm
scaled errors are
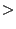 their ``low'' thresholds, but
both are still their ``high'' thresholds.
their ``low'' thresholds, but
both are still their ``high'' thresholds.
- FAIL
- if either of the RMS-norm and the -norm
scaled errors are their ``high'' thresholds.
run/* directories print a summary
of the number of ok/marginal/FAIL tests run for each target
(``1d'', ``2d'', or ``3d''). (Alas, there's
no ``master summary'' done across all numbers of dimensions.)
![]()
![]()
![]()
![]()
Next: Parameters
Up: TestInterp
Previous: Running the Tests
Contents