Next: Reading Data from Files Up: IOUtil Previous: Data Filenames Contents
Checkpointing and Recovery in Cactus
The I/O methods for arbitrary output of CCTK variables also provide functionality for checkpointing and recovery. A checkpoint is a snapshot of the current state of the simulation (i.e. the contents of all the grid variables and the parameter settings) at a chosen timestep. Each checkpoint is saved into a checkpoint file which can be used to restart a new simulation at a later time, recreating the exact state at which it was checkpointed.
Checkpointing is especially useful when running Cactus in batch queue systems where jobs get only limited CPU time. A more advanced use of checkpointing would be to restart your simulation after a crash or a problem had developed, using a different parameter set recovering from the latest stable timestep. Additionally, for performing parameter studies, compute-intensive initial data can be calculated just once and saved in a checkpoint file from which each job can be started.
Again, thorn IOUtil provides general checkpoint & recovery parameters. The most important ones are:
- IO::checkpoint_every (steerable)
specifies how often to write a evolution checkpoint in terms of iteration number. - IO::checkpoint_every_walltime_hours (steerable)
specifies how often to write a evolution checkpoint in terms of wall time. Checkpointing will be triggered if either of these conditions is met. - IO::checkpoint_next (steerable)
triggers a checkpoint at the end of the current iteration. This flag will be reset afterwards. - IO::checkpoint_ID
triggers a checkpoint of initial data - IO::checkpoint_on_terminate (steerable)
triggers a checkpoint at the end of the last iteration of a simulation run - IO::checkpoint_file (steerable)
holds the basename for evolution checkpoint file(s) to create
Iteration number and file extension are appended by the individual I/O method used to write the checkpoint. - IO::checkpoint_ID_file (steerable)
holds the basename for initial data checkpoint file(s) to create
Iteration number and file extension are appended by the individual I/O method used to write the checkpoint. - IO::checkpoint_dir
names the directory where checkpoint files are stored - IO::checkpoint_keep (steerable)
specifies how many evolution checkpoints should be kept
The default value of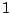 means that only the latest evolution checkpoint
is kept and older checkpoints are removed in order to save disk space.
Setting IO::checkpoint_keep to a positive value will keep so many
evolution checkpoints around. A value of
means that only the latest evolution checkpoint
is kept and older checkpoints are removed in order to save disk space.
Setting IO::checkpoint_keep to a positive value will keep so many
evolution checkpoints around. A value of 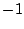 will keep all (future) checkpoints.
will keep all (future) checkpoints.
- IO::recover_and_remove
determines whether the checkpoint file that the current simulation has been successfully recovered from, should also be subject of removal, according to the setting of IO::checkpoint_keep - IO::recover
keyword parameter telling if/how to recover.
Choices are "no", "manual", "auto", and "autoprobe". - IO::recover_file
basename of the recovery file
Iteration number and file extension are appended by the individual I/O method used to recover from the recovery file. - IO::recover_dir
directory where the recovery file is located - IO::truncate_files_after_recovering
whether or not to truncate already existing output files after recovering
To checkpoint your simulation, you need to enable checkpointing by setting
the boolean parameter checkpoint, for one of the appropriate I/O methods to
yes.
Checkpoint filenames consist of a basename (as specified in IO::checkpoint_file) followed by ".chkpt.it_![]() iteration_number
iteration_number![]() "
plus the file extension indicating the file format ("*.ieee" for IEEEIO
data from CactusPUGHIO/IOFlexIO, or "*.h5" for HDF5 data from
CactusPUGHIO/IOHDF5).
"
plus the file extension indicating the file format ("*.ieee" for IEEEIO
data from CactusPUGHIO/IOFlexIO, or "*.h5" for HDF5 data from
CactusPUGHIO/IOHDF5).
Use the "manual" mode to recover from a specific checkpoint file by adding the iteration number to the basename parameter.
The "auto" recovery mode will automatically recover from the latest checkpoint file found in the recovery directory. In this case IO::recover_file should contain the basename only (without any iteration number).
The "autoprobe" recovery mode is similar to the "auto" mode except that it would not stop the code if no checkpoint file was found but only print a warning message and then continue with the simulation. This mode allows you to enable checkpointing and recovery in the same parameter file and use that without any changes to restart your simulation. On the other hand, you are responsible now for making the checkpoint/recovery directory/file parameters match -- a mismatch will not be detected by Cactus in order to terminate it. Instead the simulation would always start from initial data without any recovery.
Because the same I/O methods implement both output of arbitrary data and checkpoint files, the same I/O modes are used (see Section A6.6). Note that the recovery routines in Cactus can process both chunked and unchunked checkpoint files if you restart on the same number of processors -- no recombination is needed here. That's why you should always use one of the parallel I/O modes for checkpointing. If you want to restart on a different number of processors, you first need to recombine the data in the checkpoint file(s) to create a single file with unchunked data. Note that Cactus checkpoint files are platform independent so you can restart from your checkpoint file on a different machine/architecture.
By default, existing output files will be appended to rather than truncated after successful recovery. If you don't want this, you can force I/O methods to always truncate existing output files. Thorn IOUtil provides an aliased function for other I/O thorns to call:
CCTK_INT FUNCTION IO_TruncateOutputFiles (CCTK_POINTER_TO_CONST IN cctkGH)This function simply returns 1 or 0 if output files should or should not be truncated.
WARNING:
Checkpointing and recovery should always be tested for a new thorn set. This is because only Cactus grid variables and parameters are saved in a checkpoint file. If a thorn has made use of saved local variables, the state of a recovered simulation may differ from the original run. To test checkpointing and recovery, simply perform one run of say 10 timesteps, and compare output data with a checkpointed and recovered run at say the 5th timestep. The output data should match exactly if recovery was successful.
Next: Reading Data from Files Up: IOUtil Previous: Data Filenames Contents